Linux networking internals : Netfilter
Introduction
Linux est l’un des systèmes d’exploitation généralistes les plus utilisés au monde, et est réputé comme étant sûr et performant. Le réseau est une partie cruciale du système, car sans lui nous n’aurions pas accès à Internet ! Mais il ne faut pas oublier que des acteurs malveillants peuvent tenter de s’introduire dans ou d’espionner le système; il faut éviter de laisser la porte ouverte à n’importe qui…
Dans cet article, nous verrons donc comment Linux classifie et filtre le trafic qui transite sur une machine Linux.
Prérequis
Avant de vous lancer dans la lecture de cette article, assurez-vous d’être familier avec ces notions:
- Le réseau, particulièrement les différents protocoles, les NAT ainsi que les paquets,
- Linux en général,
- Bytecode et machines virtuelles
Bien comprendre ces concepts sera utile pour saisir le reste de l’article.
Qu’est-ce que Netfilter ?
Netfilter est le sous-système de Linux qui gère les paquets réseau reçus et envoyés sur une machine. Il s’agit plus précisément d’un framework, que l’on peut utiliser pour filtrer, modifier ou rediriger les paquets à différents endroits de leur trajet. Il forme la base des pare-feu et routeurs sur Linux.
Historique
Initialement, Linux utilisait ipfwadm et ipchains. En plus d’être peu efficaces, ces derniers modifient
directement le code réseau de Linux; le filtrage/routage était implémenté différemment pour chaque protocole.
Le code dupliqué au sein du noyau rend l’ABI instable et la maintenance difficile. C’est là que Rusty Russel, également l’auteur d’ipchains intervient
en lançant le projet Netfilter/iptables en 1998. Au fil du temps, le projet s’agrandit et la Netfilter Core Team est fondée pour superviser le développement.
Le projet est intégré au noyau Linux en 2000, pour la version 2.3.
Netfilter est créé surtout pour répondre au problème de maintenabilité et de lisibilité de ses prédécesseurs. Le framework propose en effet un cadre général de gestion des paquets, et reste donc découplé du reste du code réseau. Les étapes de traitement des paquets sont découpées en parties indépendantes, et le module de suivi des connections ainsi que le moteur de NAT sont généralisés. Netfilter apporte également beaucoup d’optimisations, afin d’augmenter les performances du réseau sur Linux.
iptables est un module développé en tandem avec Netfilter, et qui permet l’utilisation de Netfilter depuis l’espace utilisateur.
C’est lui qui gère les règles, chaînes et tables définies lors de la configuration avec l’utilitaire iptables (que nous verrons plus bas).
nftables est un nouveau module voué à remplacer iptables et une partie de Netfilter.
Il est présenté par Patrick McHardy en 2008, membre de la Netfilter Core Team, afin de réduire la duplication de code et de faciliter
l’extension à d’autres protocoles comparé au module iptables.
nftables est qualifé de “Plus grand changement pour le pare-feu Linux depuis l’introduction d’iptables en 2001” mais reste discret; il sera
ajouté au noyau Linux beaucoup plus tard, pour la version 3.13 en janvier 2014. Il est lui aussi développé par le projet Netfilter.
Fonctionnement
Netfilter s’appuie sur différents “crochets” (“hooks” en anglais) pour exécuter des actions sur les paquets, à différentes étapes du routage/filtrage. Des instructions peuvent être attachées à ces crochets, qui seront ensuite exécutées lorsqu’un paquet passe à l’endroit correspondant (e.g. en entrée, en sortie, lors d’un transfert…).
Les crochets sont placés à plusieurs étapes entre la réception d’un paquet, sa distribution au processus de la machine et l’envoi.
Modules de Netfilter
Netfilter fait une partie relativement petite du travail de filtrage de paquets; il y a tout un ensemble d’autres composants qui interagissent avec Netfilter afin de rendre son utilisation plus intuitive et de pouvoir le contrôler depuis l’espace utilisateur.
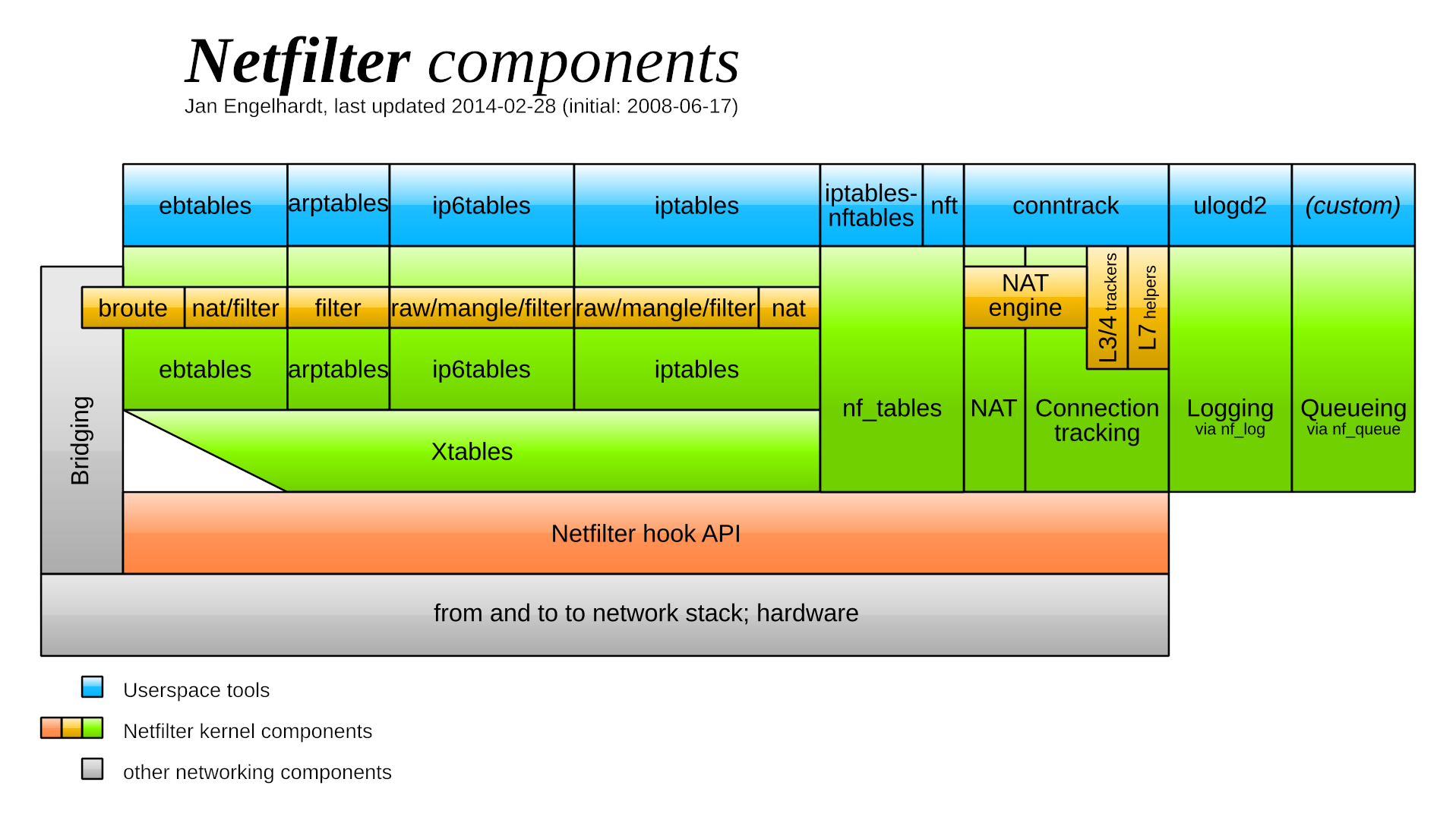
Netfilter n’est en réalité qu’un ensemble de crochets déclenchés lors de certaines étapes du trajet des paquets réseau. Le coeur est donc l’API de Netfilter permettant d’utiliser ces crochets.
Au “dessus”, on retrouve plusieurs éléments servant à communiquer avec l’espace utilisateur:
iptables, le module gérant les règles pour les paquets IPv4,ip6tables, homologue deiptablespour IPv6,ebtables, le module gérant les règles utilisées pour les ponts Ethernet,arptables, le module gérant les règles pour les paquets ARP,
Info
Les modules ci-dessus fonctionnent de la même manière et partagent beaucoup de code, qui est donc rassemblé dans un module général: Xtables.
nf_tables, nouveau module de classification des paquets, remplaçant la familleXtables,conn_track, module de traçage des connections (TCP notamment)nat, module opérant les Network Address Translations (NAT)
Tous ces modules s’appuient sur l’API fournie par Netfilter, à savoir les différents crochets. Ils peuvent être
activés ou désactivés pendant l’exécution avec modprobe.
Dans le cas de Xtables et cie., le module gère les règles, chaînes et tables (que nous verrons par la suite),
puis attache les bons morceaux de code aux crochets pour réaliser les actions demandées avec les utilitaires iptables, ip6tables, ebtables et arptables.
Pour nf_tables, le module incorpore une petite machine virtuelle capable d’exécuter un bytecode délibérément simple.
Le bytecode est généré lors de la configuration, puis est attaché aux crochets.
Cheminement des paquets
Les paquets suivent un chemin défini, avec plusieurs branches suivant leur destination. Sur le chemin des paquets, les crochets sont déclenchés, déterminant si le paquet doit être accepté ou non. Le paquet peut également être altéré (en appliquant une NAT par exemple).
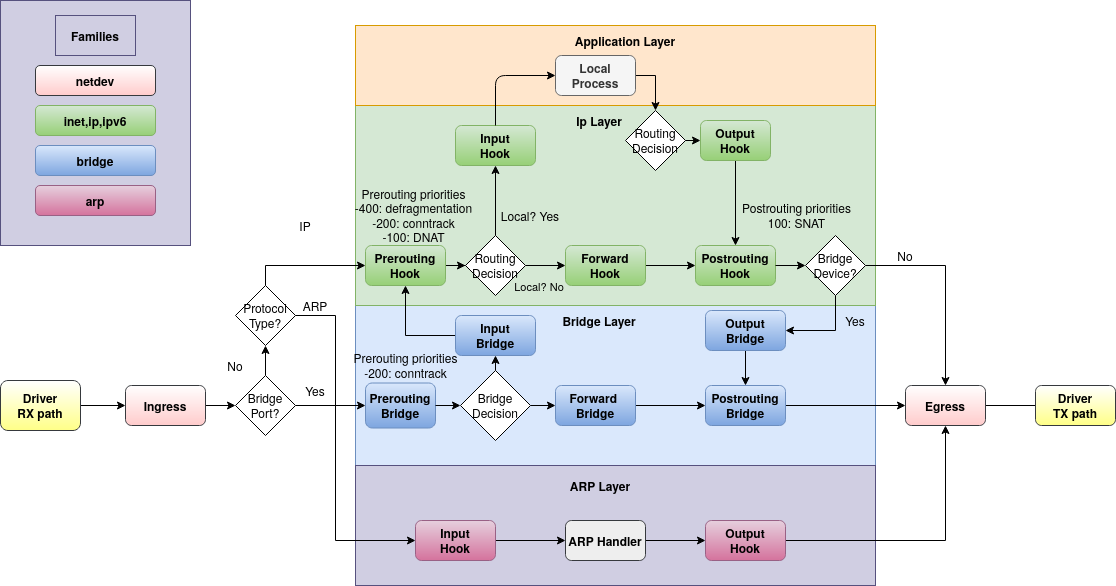
Il existe des crochets différents selon le protocole ou la destination du paquet.
Chaque morceau de code attaché à un crochet doit indiquer quoi faire avec les paquet. Il peut:
- Accepter le paquet, le paquet peut continuer sur son chemin (
NF_ACCEPT) - Abandonner le paquet, ne pas exécuter d’autres crochets (
NF_DROP) - Prendre le contrôle du paquet, ne pas exécuter d’autres crochets (
NF_STOLEN) - Mettre le paquet en file d’attente, en général pour être traité dans l’espace utilisateur (
NF_QUEUE) - Répéter l’exécution du crochet actuel (
NF_REPEAT)
NF_DROP, et NF_STOLEN se ressemblent beaucoup, mais ont une différence importante: NF_DROP retire le paquet des structures du noyau,
le supprimant au passage, alors que NF_STOLEN permet de garder le paquet en mémoire tout en arrêtant le parcours de son chemin.
Les modules Xtables et nftables s’appuient sur ces principes pour contrôler les paquets, à l’aide de chaînes de règles que nous verrons par la suite.
Configuration
Interaction avec Netfilter depuis l’espace utilisateur
Netfilter n’est pas utilisé directement par l’utilisateur: il faut passer par iptables ou nftables.
Comme dit un peu plus haut, ces modules apportent un niveau d’abstraction et introduisent le concept de règles.
Dans les deux modules, les règles sont attachées ensemble dans des chaînes, qui seront ensuite connectées à un crochet Netfilter. Les règles
de la chaîne sont appliquées séquentiellement pour chaque paquet en transit, jusqu’à ce que le paquet soit oublié (NF_DROP ou NF_STOLEN)
Les chaînes de règles sont agencées dans des tables.
Configuration avec iptables
L’utilitaire iptables interragit avec le module du noyau du même nom. Il existe cinq tables prédéfinies:
raw: Ajoutée plus récemment pour configurer les paquets afin d’éviter le suivi des connexions. Utilisée avant toutes les autres tables dans Netfilter.filter: table par défaut, utilisée pour filtrer.nat: seulement utilisée pour la NAT.mangle: Utilisée pour modifier les paquets dans des cas très spécifiques.security: Utilisée pour appliquer des règles Mandatory Access Control (MAC), dans le cadre de Security Enhanced Linux notamment.
Info
La plupart du temps, seules les tables filter et nat sont utilisées. Les autres sont utiles pour des cas bien plus spécifiques
qui sortent de l’étendue de cet article.
Ces cinq tables sont les seules disponibles et il n’est pas possible d’en créer d’autres.
Chacune de ses tables possède une ou plusieurs chaînes de base, attachées au préalable à certains crochets Netfilter. Les chaines de base ont une politique, qui indique quel comportement adopter si aucune règle de la chaîne n’est respectée. La politique a deux valeurs possibles:
ACCEPTpour accepter les paquets,DROPpour les oublier.
L’utilisateur peut créer ses propres chaînes, et peut ajouter des règles qui redirigent vers ces chaînes afin de regrouper les règles et de les réutiliser à plusieurs endroits. Les chaînes de l’utilisateur n’ont cependant pas de politique et ne peuvent pas être attachées aux crochets de Netfilter.
Les règles des chaînes sont appliquées les unes après les autres séquentiellement lorsqu’un paquet déclenche le crochet associé. Si aucune règle n’est respectée, alors le paquet est soit accepté soit oublié, conformément à la politique de la règle de base.
Exemple de pare-feu
Nous avons un petit serveur, que nous utilisons pour héberger notre site internet.
La machine exécute un seul processus: un serveur web, pour envoyer les pages du sites aux utilisateurs. Le serveur web passe par le port 80, le port HTTP par défaut. Nous voulons sécuriser un peu notre système en bloquant tout le trafic indésirable, c’est-à-dire tout ce qui n’est pas adressé au serveur web.
Il faut d’abord accepter les paquets adressés à notre serveur web:
# iptables \
--table filter \
--append INPUT \
--protocol tcp \
--match tcp \
--dport 80 \
--jump ACCEPT
Il y a plusieurs éléments:
--table filter: spécifie que l’on travaille dans la tablefilter. Ce n’est pas obligatoire puisque c’est la table par défaut.--append INPUT: C’est l’action principale à réaliser: on ajoute une règle dans la chaîne INPUT.--protocol tcp: On vérifie que le paquet est bien un paquet TCP.--match tcp: Cette option indique àiptablesqu’il faut charger le moduletcppour vérifier certains paramètres. En effet,iptablesse limite à IPv4, il ne regarde pas les autres protocoles. L’option--protocolpermet seulement de vérifier le champprotocolde l’en-tête IP, les données ne sont pas vérifiées. C’est en chargeant un module complémentaire que l’on peut inspecter l’en-tête TCP contenu dans le paquet IP.--dport 80: On ajoute la condition que le paquet doit être adressé au port 80 de notre machine (le port utilisé par le serveur web). Cette option est seulement utilisable après avoir chargé le bon module (icitcp).--jump ACCEPT: On indique la marche à suivre, ici accepter le paquet.
Le serveur étant distant, on utilise ssh. Il faut autoriser le port associé, sinon on se retrouve coincés dehors !
# iptables \
--append INPUT \
--protocol tcp \
--dport 22 \ # Port par défaut de SSH
--jump ACCEPT
Nous ne somme pas obligés de mettre l’option --match, iptables la devine avec le protocole et l’option --dport qui suit.
Ensuite il faut accepter les paquets qui viennent de connexions établies:
# iptables \
-A INPUT \
-m state \ # Charger le module d'inspection d'état de connexion
--state ESTABLISHED,RELATED \
-j ACCEPT
Si l’on omet cette règle, notre machine ne pourra plus se connecter à d’autres serveurs en tant que client. Il sera donc impossible de mettre à jour la machine.
On peut également accepter les réponses de pings (les pongs):
# iptables \
-A INPUT \
-p icmp \ # Le module 'icmp' est chargé automatiquement
--icmp-type 0 \
-m state \ # ici, on charge aussi le module 'state' explicitement
--state ESTABLISHED,RELATED \
-j ACCEPT
Tip
Cette règle permet à notre serveur de ping une autre machine, mais bloque les pings entrants. Pour accepter les pings entrants, on peut modifier cette commande comme suit:
# iptables \
-A INPUT \
-p icmp \
--icmp-type 0|8 \
-m state \
--state NEW,ESTABLISHED,RELATED \
-j ACCEPT
Pour pouvoir tester facilement, on autorise tout le trafic local via l’interface loopback:
# iptables \
-A INPUT \
-i lo \
-j ACCEPT
L’option -i spécifie l’interface qui correspond à la règle.
Enfin, on rejete tous les autres paquets entrants, en mettant la politique de la chaîne INPUT à DROP:
# iptables -P INPUT DROP
Et voilà ! Vous avez un pare-feu tout neuf !
On peut voir l’ensemble des règles comme ceci:
# iptables -L INPUT -v -n
Chain INPUT (policy DROP 58 packets, 3600 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
2073 2501K ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 icmptype 0 state RELATED,ESTABLISHED
0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
L’option -L liste les règles d’une chaîne, -v affiche plus informations et -n empêche de traduire les numéros d’adresse et de port en noms.
Il reste tout de même un petit problème: votre pare-feu sera supprimé si vous éteignez votre machine…
Pour y remédier, on peut utiliser les utilitaires iptables-save et iptables-restore.
iptables-save enregistre toutes les règles et chaînes actuellement définies dans un fichier:
# iptables-save -f pare-feu.conf
L’option -f permet d’indiquer dans quel fichier enregistrer la configuration iptables. Si elle est omise, la configuration sera affichée sur la sortie standard.
On peut restaurer les règles en chargeant le fichier avec iptables-restore:
# iptables-restore pare-feu.conf
Le pare-feu renaît de ses cendres !
Warning
Ayez le réflexe de changer la politique de la chaîne seulement à la fin de votre configuration, pour éviter de vous retrouver sans connexion et de nécessiter une intervention physique.
Configuration avec nftables
nftables est contrôlé par l’utilitaire nft. La configuration est similaire à iptables, mais apporte son lot de changements.
Contrairement à iptables, il n’existe pas de table ou de chaîne prédéfinies. C’est à l’utilisateur de les créer, puis de les attacher au bon crochet Netfilter.
La configuration peut être réalisée via la ligne de commande avec la commande nft, ou par des fichiers de configuration.
Chaque table est associée à un protocole (plus précisément à une famille d’adresses). Chaque règle peut donc manipuler des paquets uniquement d’un seul protocole, à savoir:
ip: pour IPv4,ip6: pour IPv6,inet: à la fois IPv4 et IPv6 pour simplifier la configuration dual-stack,arp: pour ARP. Permet de traiter les paquets avant le traitement de couche 3 (réseau) par la pile réseau de Linux,bridge: pour les paquets transittant par une machine (ethernet bridging)netdev: Permet dde créer des chaînes de règles rattachées à une interface réseau spécifique. Seuls les paquets provenant ou partant de l’interface définie sont traités par les règles de la chaîne.
La spécification des règles se fait via des expressions qui peuvent être imbriquées afin d’avoir un contrôle total de la configuration.
Exemple de pare-feu
Nous reprenons le même exemple: un petit serveur web, contrôlé via SSH, le trafic passant par le port 80.
Nous devons d’abord ajouter une table (que l’on appellera “firewall”) prenant en charge à la fois IPv4 et IPv6:
# nft add table inet firewall
Ensuite, ajoutons une chaîne de base qui s’appelle “base”:
# nft add chain inet firewall base { type filter hook input priority 0; policy accept; }
Ici, nous définissons le type de chaine, le crochet auquel elle est attachée, la priorité ainsi que la politique. Il y a trois types de chaîne possibles:
- Le type
filterindique que cette chaine filtrera les paquets. - Le type
natest utilisé pour faire des Network Address Translations. Seul le premier paquet d’une connexion est traité par cette chaîne; les paquets suivants restent intacts. - Le type
routepermet de rerouter les paquets dont l’en-tête IP a été modifié avant d’être accepté. Suivant le type de chaîne, seuls certaines familles d’adresses et certains crochets peuvent être utilisés.
Il y a 6 crochets possibles pour les familles ip, ip6 et inet:
ingress, qui se situe directement après le pilote de l’interface réseau d’entrée.prerouting, juste avant la décision de routage. Voit tous les paquets entrants.input, voit tous les paquets adressés à la machine et à ses processus.forward, situé après la décision de routage et voit les paquets qui ne sont pas adressés à la machine.output, voit les paquets émis par les processus locaux de la machine.postrouting, placé juste avant l’envoi des paquets sur le réseau.
Note
Les autres familles ont des crochets légèrement différents qui ne seront pas expliqués ici.
Nous pouvons maintenant ajouter les règles. Nous allons procéder comme pour iptables:
# nft add rule inet firewall base tcp dport {22, 80} counter accept
Ici, on ajoute une règle qui accepte les paquets à destination de notre machine sur les ports 22 (SSH) et 80 (HTTP). On ajoute également un compteur, qui compte le nombre de paquets et la taille totale que la règle a accepté.
# nft add rule inet firewall base ct state vmap { established: accept, related: accept, invalid: drop }
Nous ajoutons la règle qui accepte les paquets d’une connexion déjà établie.
# nft add rule inet firewall base icmp type { echo-reply } ct state vmap { established: accept, related: accept, invalid: drop }
Cette règle est très similaire à la précédente, et permet de bloquer les requêtes de ping.
Tip
Pour accepter les requêtes de ping, il suffit d’ajouter le type ICMP echo-reply à la liste des types acceptés,
et d’accepter les nouvelles connexions:
# nft add rule inet firewall base icmp type { echo-reply, echo-request } ct state vmap { new: accept, established: accept, related: accept, invalid: drop }
# nft add rule inet firewall base meta iffname lo accept
On accepte tout le trafic sur l’interface loopback.
Il faut maintenant changer la politique de la chaîne que nous avons créé pour bloquer tous le trafic indésirable:
# nft add chain inet firewall base { type filter hook input priority 0; policy drop; }
Il suffit de recréer une chaîne avec le même nom et les bons paramètres; nft va modifier la règle existante.
Tip
La commande nft create permet de créer une chaîne / table et d’afficher une erreur si elle existe déjà, au lieu de modifier
l’objet existant.
Et voilà ! Vous pouvez voir toutes les règles créées ainsi que la valeur de leurs compteurs:
# nft list ruleset
table inet firewall {
chain base {
type filter hook input priority filter; policy drop;
tcp dport { 22, 80 } counter packets 67 bytes 10742 accept
ct state vmap { invalid : drop, established : accept, related : accept }
icmp type echo-reply ct state vmap { invalid : drop, established : accept, related : accept }
iifname "lo" accept
}
}
Le format affiché ici est utilisable pour configurer nftables.
Tout comme iptables, les règles ne sont pas retenues après un redémarrage. Pour les rendre persistentes, il faut les sauvegarder dans un fichier puis les charger.
Pour sauvegarder, il suffit de mettre la sortie de nft list ruleset dans un fichier.
# echo "flush ruleset" > pare-feu.conf
# nft list ruleset >> pare-feu.conf
Tip
On ajoute ici flush ruleset, qui est une commande nft. Elle permet de supprimer toutes les règles déjà définies.
Cela évite d’avoir des duplicats ou de mélanger plusieurs règles, ce qui pourrait bloquer le système.
Pour charger, il suffit d’utiliser l’option -f de la commande nft:
# nft -f pare-feu.conf
Skadoosh !
Conclusion
Dans cet article, nous n’avons vu qu’une petite partie de l’iceberg qu’est le réseau sur Linux. Si vous voulez en savoir plus, la documentation du noyau est très complète pour comprendre le fonctionnement du réseau sur Linux.
Solutions basées sur Netfilter et cas d’usage
L’utilisation de Netfilter via iptables ou nft reste tout de même assez fastidieuse, c’est pourquoi de nombreux outils sont disponibles
pour configurer un pare-feu ou mettre en place des règles de routage.
- Uncomplicated Firewall, développé par Canonical, un front-end de
iptables/nftablesqui permet de configurer un pare-feu bien plus facilement. - Firewalld, aussi un front-end de
iptables/nftablesdéveloppé par Red Hat. - La plupart des outils de virtualisation, comme Docker, Kubernetes ou LXC, utilisent Netfilter pour gérer les réseaux virtuels des conteneurs (notamment via des ponts).
- OSSEC, un système de détection d’intrusion, contrôle Netfilter pour bloquer les adresses suspectes.
Netfilter reste le seul système de classification de paquets sur Linux, la quasi-totalité des applications est forcée de l’utiliser d’une manière où d’une autre.
Perspectives d’avenir: eBPF et bpfilter
Une nouvelle solution est apparue ces dernières années et elle arrive en force. Il s’agit de eBPF, un système de programmation dynamique directement intégré au noyau.
eBPF est une extension de Berkely Packet Filter, le “e” signifiant “extended”. BPF est un système de filtrage de paquets initialement sur BSD et dérivés (d’où le nom). Il s’est ensuite répendu aux autres systèmes Unix. Aujourd’hui, la plupart des systèmes supportent eBPF, qui vise à être le successeur de BPF.
Ce système permet de rajouter son propre code à celui du noyau lors de l’exécution, sans avoir à le recompiler ou rajouter des modules. Le sous-système permet notamment d’instrumentaliser le noyau
pour obtenir des statistiques ou repérer des problèmes de trames réseau, d’obtenir des informations de débogage et de traçage (avec notamment kprobes, uprobes…) ou pour
améliorer la sécurité (dans le cadre de seccomp, avec seccomp-bpf).
eBPF peut être attaché un peu partout dans le noyau, y compris dans Netfilter afin de filtrer les paquets.
C’est l’objectif principal de bpfilter: utiliser eBPF en tandem avec Netfilter pour filtrer les paquets. Il s’agit d’un nouveau module connecté à Netfilter et d’un utilitaire du même nom en espace utilisateur.
Il vise à rempalcer Xtables et nftables.
Il améliore la flexibilité du filtrage, de par sa nature dynamique, et permet de passer outre le chemin des paquets habituel (avec XDP, eXpress Data Path).
L’écosystème eBPF est très riche et commence à être adopté massivement. On retrouve eBPF notamment dans:
- Cilium, un système de surveillance et de traçage d’activité réseau au sein d’un cluster Kubernetes,
- Groundcover, une plateforme d’observabilité cloud-native,
- Katran, le load-balancer de Meta pour Facebook,
- Cloudflare et leur protection contre le DDoS,
- Datadog, un outil de cloud-monitoring,
- AWS et Azure, des hébergeurs cloud.
Bibliographie
Netfilter
- nftables wiki - Netfilter hooks
- Article Medium sur le flot de paquets et netfilter
- iptables tutorial (Chapitre 6: Traversing of tables and chains)
- Wikipédia (Parties History et Userspace utility programs)