Introduction
A “runner” is a relatively new term in the tech world, and now serves a central role in huge projects in complex and remote task processing, allowing the developers to have much more possibilities than with their local machine.
Nowadays, multiple technologies exist to achieve the goal of resource and time optimization that can offer a “runner”. Here is a non-exhaustive list of few well-known technologies used around the tech world:
- GitHub Actions Runners allow running pipelines on GitHub;
- Airflow Workers are part of the Apache Airflow technology, that allow to execute tasks as part of predefined workflows;
- Jenkins Agents runs pipelines in the Jenkins ecosystem;
- AWS Lambda and Google Cloud Functions are “on-demand compute service”;
- GitLab Runners allow running pipelines on GitLab;
- Celery Workers are Python-based task queues to handle asynchronous execution of functions.
Each of those example have similarities and different scopes of usage and execution. To have a better understanding of the different technologies and usage, let’s zoom and compare the last two: GitLab runners and Celery workers.
Definition
What is it?
Let’s start with a more or less formal definition of a runner. A runner is basically a software component that executes jobs or tasks in response to trigger events like schedule events, git actions or a new task in a task queue.
A runner act like an “execution engine” allowing to delegate resource and time consuming tasks, letting you also monitor the states of the different tasks that needs to be executed.
A runner also provides an isolated, repeatable, and most often parallelized environment, ensuring security against code-related problems, reliability and greater performance than a local development machine.
A runner let also the developers delegates some huge tasks, to allow executing some non-blocking work like running tests or sending a batch of emails.
Note
Note that in this article, we will use the terms runners and workers interchangeably to keep things simple and avoid confusion.
There is a subtle distinction, runner often refers to a virtual machine executing jobs at “machine level”, while a worker more commonly describes software that executes jobs at the “application level”.
What problem does it solve?
As briefly discussed at the end of the previous section, runners try to solve few problems in application development workflow: reliability, reproducibility and efficiently execute subtasks without disturbing or blocking the main workflow.
Without runners or workers, developers or applications would have some huge constraints like:
- manually run scripts on their local machine to build, test and deploy their application;
- execute long-running background tasks in the main application execution;
- handle errors, retries and logs themselves;
- difficult and mostly manual scaling.
Introducing runners propose several solutions to address the above-mentioned problems:
- automation: tasks are triggered based on events;
- segregation of duties: application main logic is separated from background tasks logic;
- scalability: runners can be easily replicated, and so load evenly distributed according to the real computation need;
- error tolerance: scenarios where task can fail due to external causes (unstable network, …) can be more easily managed thanks to specific configurations;
- environment control: jobs and tasks run in a known and reliable environment, allowing the jobs to be easily reproduced.
GitLab runner
Use case
A GitLab runner is the official GitLab version of the runner allowing the
execution of CIs/CDs on GitLab projects (defined in a .gitlab-ci.yml file at
the root of the repository).
This type of runner is designed to be used for a wide range of projects and general tasks, like building applications, testing code, deploying applications, generating reports, … The possibilities offered by this type of runner is almost infinite because it can run almost everything.
In the case of GitLab runners, its number of possibilities is offered by its level of execution. The tasks are executed almost directly on the virtual machine and the configuration is very modular, it is a general-purpose type of runner by design allowing various automations.
Ease of setup and usage
A GitLab runner installation and configuration is straightforward, and details about its installation won’t be explained here since the official documentation is well detailed about the different steps. All you need to know is that a GitLab runner is distributed via a single binary or even packages on most Linux distributions. See the installation guide for Linux packaging details, and configuration documentation for details about the unique configuration file.
During the installation, the variety of
executors (mainly how jobs are run
on the runner) allow multiple possibilities, and choosing the well known
docker let the users use compatible container images to execute every type of
tasks, make it easy to use.
It’s easy integration into GitLab (only few clicks and commands to register a runner and make it run all kind of predefined pipelines) also make it easy to set up.
In fact, those are the main reasons why this type of runner is democratized for CIs, CDs and general tasks management: easy installation, detailed documentation, many possibilities through various choice of executors, easy to integrate into an already existing infrastructure, …
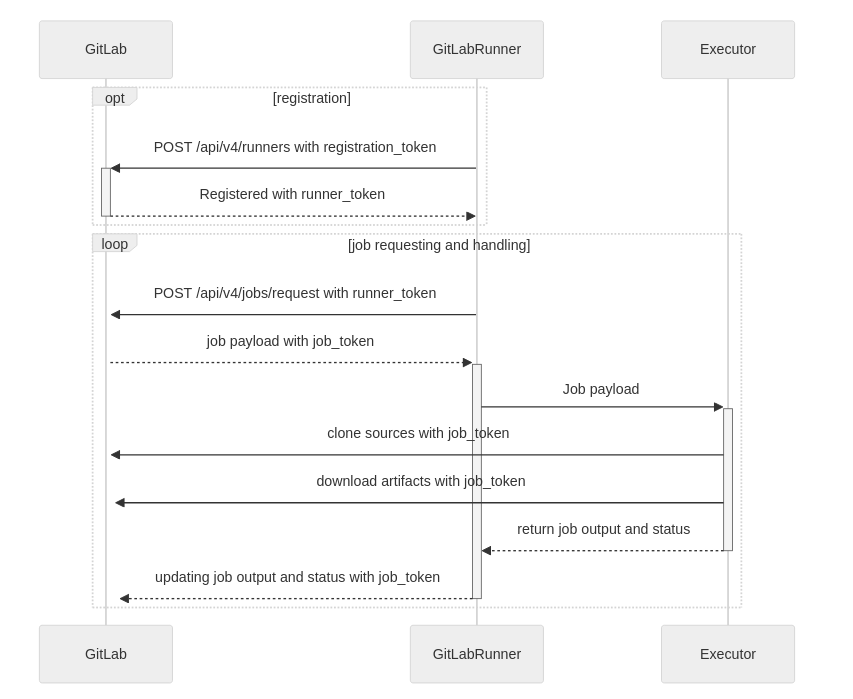
What happens when a request is made?
To give context on how this type of runner is integrated into a more global workflow, here is a short explanation on what happens during some task need to be done.
When GitLab triggers a pipeline (from a push, merge request event or other possible event), multiple things happens:
- pipeline configuration (
gitlab-ci.ymlin our case) is parsed by GitLab; - created jobs are queues and a runner regularly checks for new tasks to run;
- the multiple steps of the job are executed on the runner;
- the task eventually upload artifacts on GitLab.
Moreover, if needed and describe in the gitlab-ci.yml file, jobs can be
retried according to defined policies.
Possible issues
Even if GitLab runner is powerful, its genericity has its trade-offs and downsides:
- it’s hard to debug locally. Since this type of runner is at the machine level, it may be hard to reproduce errors locally (errors linked to the environment itself, not directly to the code since this type of error should be detected by classic tests);
- it’s heavy for small tasks. Since GitLab runner reproduces always the same environment, it needs to clone a repository, download a container if needed, setup the chosen executor;
- it might be difficult to interact with the result of pipelines, since it’s designed to be a “all in one”. Some features are available like artifacts, but they aren’t really designed to be used by other automations;
- the scalability of runners is complex, since there is mainly two
possibilities: add more runners (but it requires more hardware resources), or
use complex executors like
Docker MachineorKubernetes.
To conclude this section, GitLab Runner remains a robust choice for teams looking to automate development and deployment workflows at scale, even if, despite their genericity, it is not always the better solution.
Let’s analyze another widely used solution: Celery workers.
Celery workers
Use case
Celery is a Python-based distributed task queue, designed to delegate work from web servers or process tasks asynchronously using background workers.
It’s ideal for:
- asynchronous execution tasks like sending emails, processing files “in the background”, …
- scheduled and periodic jobs (Celery beat);
- highly integrated tasks in application;
- full workflow, since some jobs can depend on others, …
- advanced and easy monitoring (using Flower for example).
As always in the runner concept, it let the developer designate steps that are really resource or time consuming to be run in background, easing the scalability of this kind of tasks so the application “in the foreground” remain responsive, separating foreground and background tasks.
Ease of setup and usage
The installation of Celery might seem more “difficult” and “time consuming” that GitLab runner, because it does not provides “all-in-one” binaries or package. As it can be seen in the documentation, you need to:
- choose a broker;
- install Celery;
- finally run a worker.
At first, the installation of Celery might be disturbing, not knowing which broker to choose.
This type of installation has the advantage of letting you choose your technologies, mastering perfectly the deployment of workers, but it requires to know the broker technologies in the first place. This type of installation also give more freedom about monitoring and management, thing that can be appreciable in specific situations, depending on the real need.
It also ease the process of scalability, since it’s possible to only have one broker and auto-scaling workers depending on the need.
Execution workflow
To flesh out our comparison with a GitLab runner, let’s dig into the execution workflow:
- task enqueue, due to a call like
send_email.delay(...), which serializes the task and push it into the broker’s queue; - worker polling the broker for a new task (the latter keeping order of submission, ensuring reliability and consistency);
- deserialization and execution of the received task;
- storing results via the broker, if needed.
Moreover, like GitLab runners, Celery workers can automatically retry tasks according to predefined policies. Celery provides also custom error callbacks, allowing more fine grained error handling.
Possible issues
Despite everything, Celery worker isn’t the magical solution everyone is searching for…
Here is a list of some issues that may hinder its use:
- the most obvious one is that Celery is a Python-based application, so you need to have a Python application (or at least the part managing the tasks that need to be executed);
- broker can be an issue, since it creates a “new point of failure” as it is external to Celery;
- concurrency problems may occurs through multiprocessing tasks with file reading for example, or memory problems (see here for more details);
- even if the monitoring is possible, it requires external tools, with themselves with a new configuration.
There challenges don’t negate Celery’s key strengths
To conclude this section, it outlines how Celery workers fulfill the previously presented general runner, contrasting mainly on their lightweight and their integration directly inside applications.
Comparison
| Aspect | GitLab Runner | Celery Worker |
|---|---|---|
| Use case | Agent for GitLab CI/CD pipelines. It allows the execution of generic tasks allowing the build, test and deployment of all types of projects through a configuration file, and triggered on GitLab events (commits, merge, …) | Distributed task queue for background processing (like sending email). Used in Python apps for asynchronous tasks, works via a message broker to manage task queue |
| Execution environment | Runs as a standalone package on a virtual machine (or a container). Runner is registered on a GitLab project or group and waits for jobs to run. It uses configured executors to isolate jobs, prepare the environment (consistent across multiple jobs with the same configuration for sake of reproducibility), run the needed script and get back to GitLab with the logs, results and potential artifacts. | Runs as one or more long-lived worker processes. Each worker is linked to a broker to fetch tasks to execute. Within the worker, tasks are executed according to the chosen concurrency pool in the configuration. If a task fails, Celery can rerun it and/or execute custom error handling functions. Tasks can be easily monitored with external tools |
| Project integration | GitLab runners are integrated in projects inside the development workflow, in git repositories. It helps validate the newly created code and deploy it according to the gitlab-ci.yml configuration file. |
Celery is integrated at the code level. It is used during the phase of usage of the app to lighten the whole app delegating time and resource consuming tasks to “background” workers. |
| Scalability | A runner can support multiple jobs at the same time, but its “machine-level” design makes it more resource consuming, and a bit less easy to scale because it might easily need a lot of hardware resources. | Celery is designed for horizontal scaling allowing a lot of workers in parallel. Its design with a message queue and a broker allow easy scaling. Moreover, a single worker can execute multiple tasks thanks to parallelism, and need less resources than a GitLab runner to execute the exact same task. |
In short, Celery workers could be considered like “inside” runners, while GitLab runners like “outside” runners.
Summary
The article presented in details two types of runners, GitLab runner and Celery worker may differ in their implementation, but they serve a common purpose: offering the possibility to work “aside” the main workflow, allowing performance optimizations and reliability. In the modern world of software engineering, runners are essential to ensure efficient CI/CD pipelines, task automation and ensuring responsive application delegating many tasks to dedicated “executors” that are specialized in running predefined tasks.
Through this article, we firstly explained the concept of a runner, and then we focused on two specific implementations of this concept: a GitLab runner and a Celery worker. Those two implementations have been chosen because even if they serve a common principle, they offer radically different approach in the resolution of the problems exposed earlier.
GitLab runner, fully integrated into GitLab workflow, have been chosen to “represent” the general runners, designed to be compatible with almost everything, and to be a “machine-level” runner, reproducing the wanted standardized environment each time, to execute build phases, tests, deployment and many other tasks on triggering GitLab events. Their tight integration into GitLab makes them an obvious choice for automating development pipelines, while their flexibility through different executors (like Docker) makes them capable of handling virtually any type of automation task. However, their machine-level architecture and general-purpose design come with a cost, because the reproduction of a standardized environment can be complex, as much in terms of time than hardware resources that can add more complexity to large scaling.
Celery Worker, by contrast, is more lightweight and better suited for integration directly into Python-based applications. The strength of this time of worker is its integration directly into the source code, allowing easy transfer of heavy tasks during the runtime, rather than the “pre-runtime” phase like GitLab runners. This structure also make them more easy to horizontally scale thanks to the broker that “centralize” the “to-do list” of the multiple workers, also integrating multiple possibilities to finely manage errors (retries, custom error callbacks, …) and monitor tasks and brokers. Moreover, it doesn’t need to reproduce a standardized environment at each task, because it’s directly integrated into the flow of the application, and therefore has a known environment that is always the same (a Python app in our case, but this logic can be applied to other similar types of workers).
On the other hand, Celery is a bit more difficult to set up, and more error-prone to mistakes in the configuration, since it’s not a single standalone “package”, but a composition of multiple services (broker, workers, and the source code of the application itself).
Conclusion
The final word of this article is that, even at first glance, a general-purpose runner like GitLab runners could be the “magical solution to everything”, there is no ideal solution that can solve all the problems, and the chosen implementation should be driven based on the real usage of the concerned workflow. You might even need a combination of multiple types of runners, since they do not operate the same things at the same steps in the application life cycle.
In conclusion, understanding the concept of runners, and their different implementations, is crucial to build efficiently and efficient softwares.