Les threads sont un concept important dans l’architecture logicielle.
Ils permettent d’exécuter du code en parallèle au sein d’un même programme.
Ils sont apparu pour la première fois dans la littérature scientifique en 1967 par Victor Alexander Vyssotsky1.
Ils désignent le plus petit ensemble d’instructions indépendent executé par le scheduler.
Cependant avec l’apparition des processeurs à plusieurs coeurs, maintenant ils désignent plus le fait de paralléliser des tâches au sein d’un programme.
Une des implémentations les plus connues est celle de la glibc.
Elle implémente la norme POSIX Thread2 pour plusieurs plateformes.
Dans cet article, nous nous intéresserons à son implémentation pour Linux.
La structure pthread.
Avant toute chose, il faut présenter la struct pthread.
Cette structure représente l’état du thread et est utilisée en interne.
Elle contient une multitude d’informations.
Elle est composé d’un header qui est unique pour chaque plateforme.
Par exemple pour l’architecture x86_64,
elle contient un pointeur sur sa structure pthread,
des pointeurs à des emplacements mémoires spécifiques au thread, etc.
Sur l’architecture ARM64,
elle contient uniquement un pointeur dtv
et un pointeur sur une zone mémoire “privée”.
Elle contient beaucoup d’informations utiles au bon déroulement du thread comme par exemple :
- L’adresse,
les paramètres
et le résultat de la fonction démarrant le
thread. - L’identifiant du
threaddonné par lekernel - Plusieurs paramètres liés au
threadcomme par exemple le paramètres duscheduler, si l’utilisateur fourni lui même unestackou si tous les évenements doivent être reportés.
Cette structure est très complète et représente le coeur d’un thread.
Comment un thread est créé ?
|
|
C’est cette fonction qui va créer le thread.
start_routine est un pointeur de fonction qui pointe vers la fonction qui va être démarrée par le thread.
pthread_t est un alias vers unsigned long int, d’après la documentation c’est l’identifiant du thread.
Cependant, c’est plus qu’un simple identifiant, c’est l’adresse mémoire où se situe la structure pthread !
Concretement, quand la glibc a besoin de trouver la structure pthread à partir de son identifiant,
elle va le caster d’un unsigned long int vers une struct pthread * 3.
Ce moyen permet facilement de récuperer cette structure.
Mais alors qu’est-ce qui se passe derrière cette fonction ?
Les différentes allocations de mémoires.
Pour que le thread fonctionne correctement, avant sa création, il faut lui allouer de la mémoire.
Elle comporte 3 parties distinctes : la guard, la stack et le TLS (Thread Local Storage).
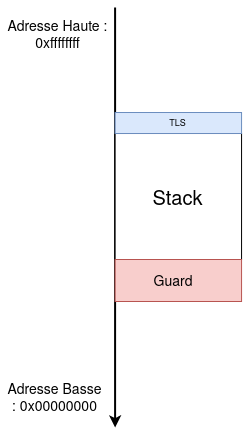
Avant d’en allouer, la glibc va regarder dans son cache interne :
- Si une zone mémoire équivalente est disponible, alors la
glibcva l’utiliser. - Sinon, la
glibcva faire appel au syscallmmappour l’allouer.
Par défault, sa taille est donnée par getrlimit(2).
Sur mon système, elle est de 8388608 octets.
Le Thread Local Storage
En haut de la zone mémoire se trouve le Thread Local Storage.
Elle permet d’avoir des variables locales au thread.
La glibc va y placer en premier la structure pthread.
La particularité cet emplacement est que pour les processeurs x86, le registre fs va contenir l’adresse la plus haute,
c’est-à-dire l’adresse où se situe pthread.
À la base, ce registre servait pour mettre en place la GDT.
Cependant, dans les noyaux linux récents, elle n’est quasiment plus utilisée de par l’abandon de la segmentation au profit de la pagination.
Il sert maintenant à accéder facilement à la structure pthread:
|
|
Comme on peut le voir, le define va chercher l’adresse à l’offset $10$,
ce qui correspond au champ self de la structure tcbhead_t.
Elle contient l’adresse mémoire de la structure pthread.
Mais comment est mis à jour le registre fs ?
Il a deux manières de le mettre à jour :
- Pour le thread principal (ou le
main thread), c’est grace au syscallarch_prctl(2)avec l’argumentARCH_SET_FS. - Pour les threads créés grace
pthread_create, c’est le syscallclone(2)qui le met en place.
Cela permet facilement et rapidement d’accéder à son propre thread.
Il existe plusieurs cas où il est nécessaire d’accéder à son propre identifiant,
on peut citer par exemple les logs qu’il est plus facile d’analyser avec le thread id.
La stack d’un thread
Chaque thread à une stack qui lui est dédiée.
C’est un espace mémoire pour stocker les variables locales, notamment dans les fonctions.
Sur les processeurs x86, elle grossit vers les adresses basses (c’est-à-dire vers $0x00000000$).
La guard d’un thread
La guard est un garde fou d’environ une page où on ne peut ni lire ni écrire.
Elle sert principalement à éviter que la stack ne déborde sur les autres zones de la mémoire.
Le sycall clone.
Le syscall qui va “créer” le thread est clone3(2).
Il va dupliquer le processus en cours et va permettre de partager certaines ressources au processus fils.
Ainsi le processus fils aura accès aux mêmes file descriptor, à la même address space, la même table de signaux que son processus père, etc.4
Il va aussi indiquer au kernel où sera la stack et la TLS du nouveau thread.
On pourrait penser que logiquement, le fils n’aura pas le même PID que son père car le processus est “cloné”.
Il s’avère que le PID dans l’espace utilisateur n’a pas le même sens dans l’espace noyau.
Dans cet espace, il se nomme TGID (ou Thread Group Identier) mais porte le nom de PID dans l’espace utilisateur.
Cependant, chaque thread créé par clone3(2) a des PID différents mais ils ont les même TGID dans l’espace noyau.
Cette différence est apparue à la version $2.4$ du noyau Linux afin de supporter entièrement les threads POSIX.
En effet, les threads noyaux ne respectent pas entièrement cette norme notamment sur la gestion des signeaux ou les primitives de syncronisation.
RedHat, par la suite, a écrit une norme pour les threads noyau appelée NPTL (Native POSIX Thread Library).
Ce contraste vient donc de l’implémentation de deux normes différentes.
La syncronisation entre les threads.
Tout repose sur le syscall futex(2) (Fast User-Space Locking) :
|
|
Il va permettre de bloquer le thread en cours jusqu’à qu’une certaine condition devienne vraie.
Le premier paramètre (uaddr) est une adresse mémoire qui va contenir le futex.
On peut voir ça comme un jeton de $32$ bits (même pour les plateformes $64$ bits) situé dans de la mémoire partagée.
La glibc utilise principalement deux opérations:
FUTEX_WAIT_BITSETva faire attendre lethreadjusqu’à ce qu’ont le réveilleFUTEX_WAKEva le réveiller.
Une bonne analogie est celle d’une notification.
Le thread est “endormi” (FUTEX_WAIT) jusqu’à ce qu’on le notifie (FUTEX_WAKE).
Cependant, on ne peut le notifier qu’avec le bon jeton (futex).
FUTEX_WAIT_BITSET offre plus de contrôle que FUTEX_WAIT sur quels événements peuvent le réveiller.
Généralement la Glibc utilise le flag FUTEX_BITSET_MATCH_ANY pour se réveiller quel que soit l’évènement déclenché.
La fin d’un thread…
Pour attendre qu’un thread se finisse, on peut utiliser la fonction pthread_join(3).
Pour ça, elle va attendre que le thread mourant le réveille grace au syscall futex.
Le futex utilisé est localisé dans tid de la structure pthread.
Cependant, le thread mourant ne réveillera jamais la fonction pthread_join(3)5.
Aucun n’appelle au syscall futex ne sera effectué.
Quelle est donc cette sorcellerie du diable ?
Le tour de passe-passe se trouve dans la création du thread.
L’un des paramètres de clone3(2) quand le thread va être créé est CLONE_CHILD_SETTID.
Ce paramètre va indiquer au kernel où écrire l’identifiant de thread.
En l’occurrence, la glibc lui indique de l’écrire dans le champ tid, qui aussi utilisé comme futex par la fonction pthread_join(3).
De plus, le paramètre CLONE_CHILD_CLEARTID est passé à clone3(2).
Quand le thread va mourir, grace à ce paramètre, le kernel va réaliser deux actions :
- Effacer l’identifiant du
threadde la mémoire - Envoyer une notification de réveil où se situait l’identifiant du
thread.
C’est cette deuxième action qui va réveiller la fonction pthread_join(3).
Le thread peut mourir tranquillement.
Conclusion
L’implémentation de la glibc des thread POSIX est complète et efficace sur Linux.
Elle est facilement utilisable par les développeurs et offre beaucoup de contrôle sur les threads.
De plus, elle est souvent utilisée derrière la class thread en C++.
Ainsi dans cet article, nous avons pu voir la vie d’un thread, de sa naissance jusqu’à sa mort en passant par son principal moyen de synchronisation.
Cependant, la glibc a dû faire face à d’autre problématiques notamment une très important qui pourrait faire l’objet d’un futur article :
la réorganisation des instructions par le CPU ou le compilateur…
Annexes
-
https://en.wikipedia.org/wiki/Victor_A._Vyssotsky “Victor Alexander Vyssotsky” ↩︎
-
https://standards.ieee.org/ieee/1003.1c/1393/ “Standard for Information Technology–Portable Operating System Interface (POSIX(TM)) - System Application Program Interface (API) Amendment 2: Threads Extension (C Language)” ↩︎
-
Voici un example ici : https://elixir.bootlin.com/glibc/glibc-2.37/source/nptl/pthread_join_common.c#L40 ↩︎
-
Les flags utilisés pour
clone3(2)sont trouvable ici : https://elixir.bootlin.com/glibc/glibc-2.36/source/nptl/pthread_create.c#L277 ↩︎ -
Un
straced’un cycle complet d’unthread:clone3({flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, child_tid=0x7fee4edff910, parent_tid=0x7fee4edff910, exit_signal=0, stack=0x7fee4e5ff000, stack_size=0x7fff00, tls=0x7fee4edff640}strace: Process 78549 attached => {parent_tid=[78549]}, 88) = 78549 ... [pid 78548] futex(0x7fee4edff910, FUTEX_WAIT_BITSET|FUTEX_CLOCK_REALTIME, 78549, NULL, FUTEX_BITSET_MATCH_ANY <unfinished ...> ... [pid 78549] clock_nanosleep(CLOCK_REALTIME, 0, {tv_sec=10, tv_nsec=0}, 0x7fee4edfee00) = 0 ... [pid 78549] exit(0) = ? [pid 78548] <... futex resumed>) = 0 [pid 78549] +++ exited with 0 +++ exit_group(0) = ? +++ exited with 0 +++On voit bien que le
futexpour réveiller lethreadn’est jamais apelé. ↩︎