Prerequisites
Knowledge of the notions below is recommended:
- Basic level in C language (for code examples or kernel code exploration)
- Basic level in x86 assembly (for the last chapter only)
- Basic Linux system knowledge (file descriptors, notion of privilege rings, scheduling, …)
This article will be technical. However, even if you’re not comfortable with those notions, you could still learn something interesting!
Introduction
perf(1) is a performance analysis tool for Linux.
It is used to gather information about certain kernel events.
Since perf is implemented inside the Linux Kernel, it makes sense that it can gather metrics related to the kernel, such as scheduling information.
However, how is perf able to gather information about hardware, such as how many instructions did my CPU execute?
In this article, we will take a look at how perf is implemented inside the kernel and explain how it can obtain such information. We will go through 2 layers. Firstly, we will explore what kernel interface perf uses. Secondly, we will explore how it gathers CPU-related metrics. For those two layers, I will reimplement a subset of what perf does, using what I learned. I’ll provide the sources of any code I show.
This article will be more on the exploratory and fun side. If you do not know about perf, you will learn how to use it a little, and some of its capabilities. Moreover, you will learn the basics of how to use the interface the kernel gives us to monitor applications. But the main point, fetching the CPU metrics directly, has no direct application.
Perf
What is perf(1)?
As stated before, perf(1)1 is a performance analysis tool for Linux.
It is a CLI tool with a LOT of commands (seriously, just type perf in a terminal to see).
It is used to analyse what a program is doing.
Amongst other things, perf can answer the questions:
- “What part of my program takes the most time on the CPU?”
- “How many times is X kernel function called”
- “How many instructions did my program take to execute?”
Perf is a very general and powerful profiling and tracing tool for both kernel and userland. The goal of this article is not to present the different things that perf is able to do, as I’m not knowledgeable enough on this topic. However, if you want to learn more about perf, I’d encourage you to take a look at Gregg Brendan’s page about the tool2.
Perf is implemented in the Linux Kernel, under tools/perf3. It instruments in-kernel events by either:
- Counting them (available with
perf stat) - Sampling them (available with
perf record)
perf record outputs a perf.data file containing data that can be visualized with different tools (like perf report, or flamegraphs4).
Sampling is very useful to profile a program. For instance, this would be the way to understand what part of my program spends the most time on CPU.
Once again, Brendan Gregg provides a list of different usage of perf5 if you would like to know more about this.
Ladies and gentlemen, this is your kernel speaking
We said that perf instruments in-kernel events, but what do I mean by that? In-kernel events are an interface used for kernel instrumentation. Those events may be used by other tool to provide an analysis points when they arise. This could be used to increment a counter when something happens (a new process is created), or log when a certain function is called (tracing).
Here are some of the different event types that exists:
- Hardware Events: Like CPU Performance Monitor Counters (i.e. Instructions, CPU-cycles, etc.)
- Software Events: Events based on what the kernel is doing (i.e. CPU migrations, minor/major faults, etc.)
- Kernel tracepoints
- Static and Dynamic tracing
- Timed Profiling: Snapshots of a program, gathered via
perf record. - …
Brendan Gregg did an excellent diagram6 showing the different event sources:
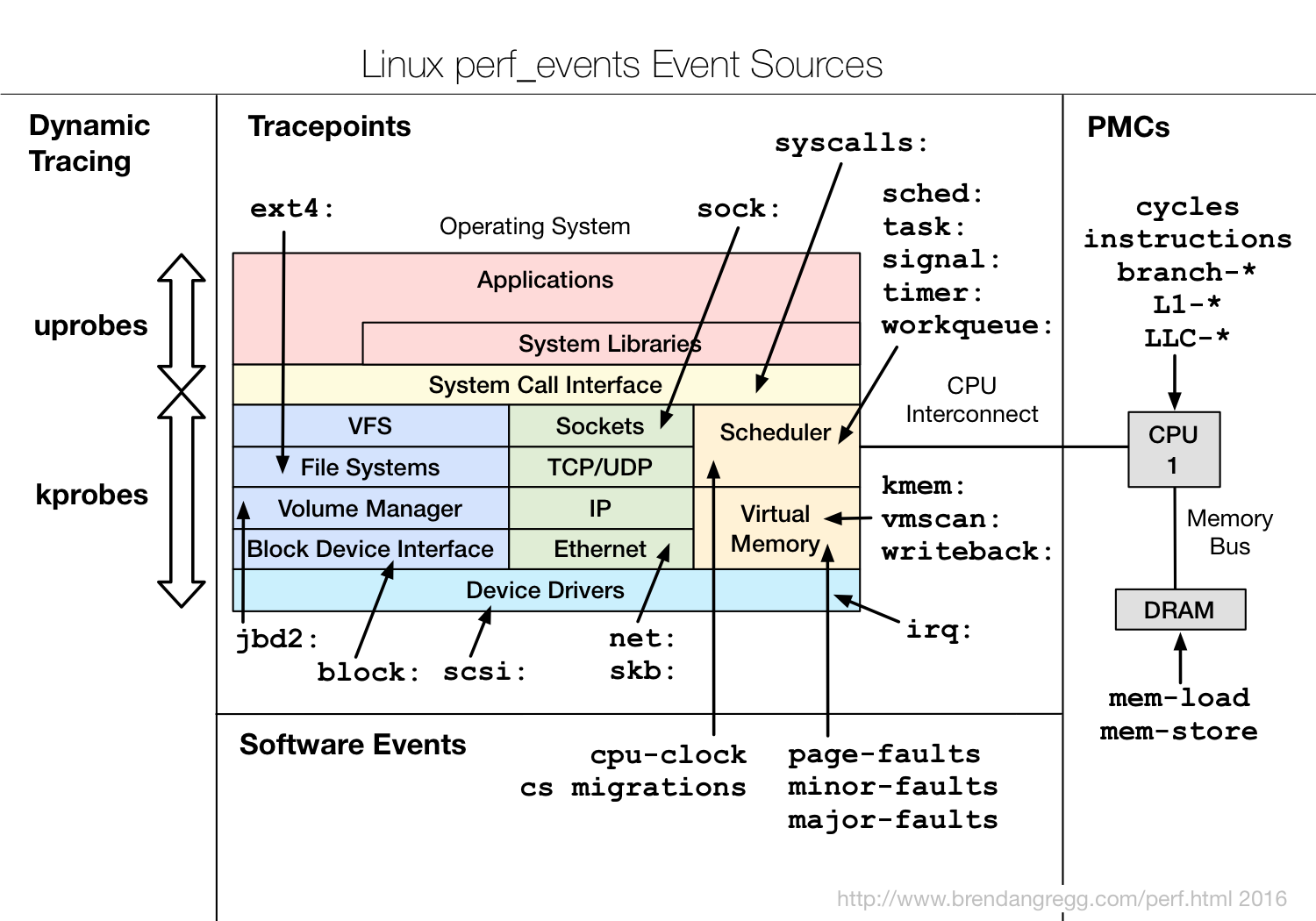
We can get a full list of the supported events with perf list.
However, we’re only interested in hardware events today.
Here is a list of them:
42sh$ perf list hw
List of pre-defined events (to be used in -e or -M):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
So, how many instructions did my program take?
In order to answer this question, we will use perf stat.
perf stat runs a command and gathers performance counter statistics.
It will not create snapshots of the program like perf record does, but only increment counters.
You can invoke it like so: perf stat -- <command> [args...].
So let’s use it!
42sh$ perf stat -- sleep 5
Performance counter stats for 'sleep 5':
0,80 msec task-clock:u # 0,000 CPUs utilized
0 context-switches:u # 0,000 /sec
0 cpu-migrations:u # 0,000 /sec
101 page-faults:u # 126,184 K/sec
1 125 867 cycles:u # 1,407 GHz
1 175 647 instructions:u # 1,04 insn per cycle
231 273 branches:u # 288,939 M/sec
9 705 branch-misses:u # 4,20% of all branches
TopdownL1 # 28,5 % tma_backend_bound
# 20,3 % tma_bad_speculation
# 31,2 % tma_frontend_bound
# 20,1 % tma_retiring
5,001459448 seconds time elapsed
0,000000000 seconds user
0,001381000 seconds sys
Here, we can see the different values for some events. We have software events such as the number of context-switches, CPU-migrations or page-faults and we have hardware events such as the number of CPU cycles, or instructions. We can also see the real time elapsed, as well as the CPU time elapsed, spent in userland (user) or in the kernel (sys).
For instance, we can see that the command sleep 5 used 1 175 647 instructions.
Now that we’ve familiarized ourselves with perf, let’s take a look at how it works!
How does Perf works?
perf_event_open, or how to cut my finger
Inside the Kernel, perf uses an interface named perf_events.
Indeed, the implementation of hardware events is, surprisingly, dependant on the architecture.
By creating a layer of abstraction, it is possible to create an interface that developers can use to write performance monitoring applications that will work across different platforms.
This is exactly what perf does! More precisely, the Linux Kernel design notes7 explains that perf uses the perf_event_open(2) syscall.
Let’s try to gather the number of instructions that a program took using this syscall.
When using perf_event_open(2), we ask to monitor 1 specific metric for 1 specific type.
For instance, the instruction count (the metric) of our CPU (which means hardware type).
perf_event_open(2) returns a file descriptor from which we can read the metric we asked to monitor.
In our case, this will be the instruction count.
We can also control this fd with ioctl(2).
This enables us to reset, enable and disable the counter.
perf_event_open(2)’s manpage provides an example measuring the number of instructions done by a printf call.
Here it is slightly modified and annotated by me:
|
|
First, we initialize a struct perf_event_attr.
It is used to inform perf_event_open(2) what metric and type we want to monitor, as well as other parameters.
In this example, we exclude the kernel and hypervisor from the monitoring to focus only userland code.
We also disable the counter by default, as we’ll enable only when needed to reduce noise.
Then, we reset and enable the counter right before the call to printf.
Immediately after the call is done, we disable the counter and read from it using the fd.
Nothing too shabby! However, the “real” perf measures an entire command, not just a call to printf.
Let’s modify the code to be able to monitor a program then.
The problem is: we want to monitor a program while interfering with it as little as possible.
We’ll fork the process and call exec(2) in the child to be able to launch and control the command.
However, we do not want to take into accounts instructions made by the parent process.
To solve this problem, the struct perf_event_attr has a member: enable_on_exec.
It automatically starts the monitoring after a call to exec(2) is executed.
What we need now is for the children to inherit the monitoring.
This can be done with the inherit member of the struct.
Finally, we call perf_event_open with the PERF_FLAG_FD_CLOEXEC.
This flag ensures that the fd is closed when the call to exec finishes.
And we’re done! Here is what our mini perf looks like:
|
|
Let’s compare the output of my program and the one of perf stat!
My version:
|
|
Perf stat (the option -e is only focus on the instructions event):
|
|
We get a number of instructions comparable to the one of perf. This result is also stable across multiple runs, which is pretty nice.
Now that we’ve seen how to use perf_event_open(2), let’s dive into where it gathers those metrics.
Performance Monitoring Counters, or deciding to shoot my own foot instead
The answer is: Performance Monitoring Counters (abbreviated PMC). PMCs are specific registers inside the CPU that expose different performance related metrics. They have the advantage of having a very low overhead, which means we have little interference with our program’s execution.
Now, we’ll need to get architecture specific.
My laptop has an Intel Core i7 11th generation CPU (previously known as Tiger Lake architecture).
PerfMon8 exposes all the performance monitoring events available across the different Intel CPU architectures.
Looking at the ones for the Tiger Lake, we can see at the top INST_RETIRED.ANY, which is the number of retired instructions.
PerfMon exposes A LOT of metrics compared to what perf list showed us earlier.
However, it is still possible to monitor the events that are not listed with perf by specifying raw counters.
More on that at this link9.
Since different architectures mean different implementations of the PMCs, let’s take a look at our beloved Intel Software Development Manual10 to understand how ours work.
Knocking on your CPU’s door on a Sunday night
We have two sections of interest, exclusively inside of Volume 3. The first one is section 2.8.6 “Reading Performance-Monitoring and Time-Stamp Counters”. This section is only a few pages long and describes how to set up a PMC in broad details.
Individual counters can be set up to monitor different events.
This means we set up one counter to follow one event type, akin to what we did with perf_event_open(2).
To select an event type, we use the instruction wrmsr to write in one of the available IA32_PERFEVTSELx Model Specific Register (MSR).
This will set the corresponding IA32_PMCx MSR to gather this event type.
We can then use the rdpmc instruction to read thisIA32_PMCx MSR.
Each logical processor has its own selection and PMC registers.
The layout for those registers is explained in section 20 “Performance Monitoring”. This section contains two interesting subsections: namely 20.2 “Architectural Performance Monitoring” and 20.3 “Intel Core Performance Monitoring”.
Architectural performance monitoring is performance monitoring that behaves consistently across micro-architectures.
While the processor evolved, different version of the APM were created.
Each version brought new features, and retain backward compatibility.
Our version of the APM can be found with the instruction cpuid:
|
|
I’m version 5 :>
As stated before, in order to set up a counter, we will write a value into one of the IA32_PERFEVTSELx MSR.
The layout of these registers is explained in section 20.2.1.1, which is the first version of the APM, in table 20-3.
Whenever I name a table, I would suggest looking at the corresponding table in the Intel Software Developer’s Manual10.
I was unsure if a screenshot of the manual abides to the CC-BY-SA license, so I preferred to not include them in.
The registers start at fixed address across microarchitectures (186H).
The fields that interest us are the event select (to select the event type) and the umask (which is dependent on the event type). Table 20-1 lists them for each supported event name.
In our case, we need to set the umask to 00H and the event select C0H.
Now, to read this counter, we need to read the corresponding IA32_PMCx MSR.
Its address is also fixed across microarchitectures and starts at 0C1H.
However, its size varies.
What I described before is only the capabilities of the Architectural Performance Monitoring Version 1. Version 2 adds mechanism to ease our development:
- Fixed control Registers, already programmed to monitor a certain type of event (describe by table 20-2)
- Global Control Registers, to enable and disable several PMC at once (described by table 20-3)
We will not use the former, as I want our example to be more general.
I will not explain the capabilities added after version 2, as I’m not knowledgeable enough about them.
Great, now we know how everything works.
We know that we should first program a register to select an event type, and then read the associated PMC register to get the count.
Since those registers are MSR, we can use the rdmsr and wrmsr instructions to read and write to them.
There is just one problem.
These instructions must be executed at privilege level 0 or in real-address mode.
I’m not a kernel module, neither do I know how to use real-address mode.
While the latter may not be tricky, I did not have time to look into it when preparing this article.
However, we’re not done yet!
The kernel exposes an interface to access msr registers: msr(4).
For each of our CPU, we have a file named /dev/cpu/CPUNUM/msr that supports read and write operations.
To access a certain MSR, we simply have to read and write 8 bytes by 8 bytes, to an offset corresponding to the address of the MSR.
Finally, let’s write a program that will count how many instructions a program uses!
|
|
Let’s see how it goes:
|
|
That’s a lot more than we have earlier.
The number of retired instructions also varies dramatically across multiple runs.
However, this result is not surprising.
Here, we only asked to monitor all the instructions ran on a single core.
This has two downsides.
First, we have no guaranty that our program will run on this core.
Second, we will monitor every instruction by every program on this core.
We do not want to set a specific CPU affinity (sched_setaffinity(2)) to stick our program to one core, nor change the scheduling policy, as this would alter our program’s execution.
While there might be an easy way to find on which core our program is executing, as far as my current knowledge goes, I do not see an easy way to monitor only one program. I also do not have the skills necessary to seek more into Linux Kernel code for this. Maybe I should use perf to learn how perf works, who knows? :^)
But, we succeeded! We finally managed to read a PMC register.
Conclusion
Phew, we made it!
We saw that perf(1) is a performance tool analysis written in the Linux Kernel.
It uses the perf_event system inside the kernel to provide for an abstraction layer for loads of different events types
For hardware events specifically, CPUs offers registers (PMC) that are programmable to monitor certain events.
And we managed to use both, more or less precisely!
There are still fascinating questions to answer and topics that I could not cover:
- How to group different file descriptors given by
perf_event_open, in order to make our example more viable? - How can
perf_eventmonitor PMCs for a specific program? Has it something to do with the scheduler? - How to sample events with PMCs, and how to count the timing between two events?
- And to be able to dive deeper into this topic, how to trace a syscall to understand what it does?
My goal was to disambiguate how perf is able to get statistics directly from hardware. As such, we did not even scratch the surface of the cool things that perf, or PMCs, let us do.
I hope I succeeded in sharing my enthusiasm for this topic! This article was very interesting to do, and I’m glad I could use some tools seen in our classes in order to understand how perf works (thank you strace). Code examples are available on my github11.
Particular thanks to Brendan Gregg who provides many resources to vulgarize perf and the kernel interface.
Thank you for your time!
-
Perf’s man page: https://www.man7.org/linux/man-pages/man1/perf.1.html ↩︎
-
Brendan Gregg’s page about perf: https://www.brendangregg.com/perf.html ↩︎
-
Perf’s source code: https://elixir.bootlin.com/linux/v6.11.5/source/tools/perf ↩︎
-
Flamegraphs: https://www.brendangregg.com/flamegraphs.html ↩︎
-
Perf examples: https://www.brendangregg.com/perf.html#OneLiners ↩︎
-
Perf_event Event sources: https://www.brendangregg.com/perf_events/perf_events_map.png ↩︎
-
Perf’s design notes: https://elixir.bootlin.com/linux/v6.11.5/source/tools/perf/design.txt ↩︎
-
PerfMon: https://perfmon-events.intel.com/# ↩︎
-
Perf’s Raw counters: https://www.brendangregg.com/perf.html#CPUstatistics ↩︎
-
Intel Software Developer’s Manual: https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html ↩︎ ↩︎
-
Article’s code example: https://github.com/Seowlfh/miniperf ↩︎