This article introduces the clean architecture, a versatile architecture approach which can be used to build distributed and embedded systems.
The myth of the agility
During our years at EPITA, we have been told: “Agile good, V cycle bad” (besides DO-178 course).
So, when starting a new project, we just go directly agile and code after reading the project requirements twice.
That’s how one ends up with a bad myfind (an EPITA project), and hates TDD, since the test suite was fully refactored four times in one week.
This could have been avoided by drawing the architecture before coding.
Indeed, spending time defining the main components of the app, how they interact with each other and defining their interfaces avoids modifying critical functions and their tests all the time.
Obviously, the architecture (and thus the design) could change a little, but it should be the backbone of the piece of software being built.
Being agile is not going from a skateboard to a bike, and a bike to a car. It is going from a old rusty car to a beautiful modern car.
Now that we know that we need architecture, how do we create one?
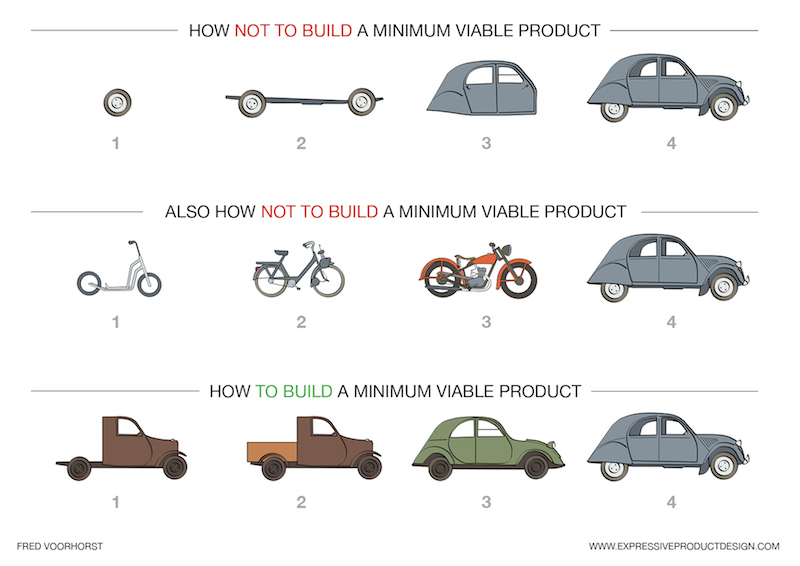
Picture found here
What is clean architecture ?
The simplest (and most popular) architecture approach is the n-tier architecture.
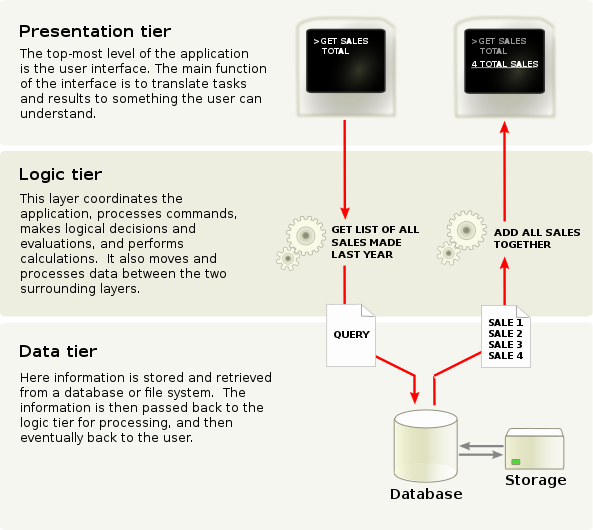
Picture from Wikipedia
Even though n-tier architecture is great to make something work fast, it introduces some major issues:
- It makes code hard to understand, since the guidelines of this architecture are vague. For instance, a database cache could be in the logic or database tier.
- It is not suitable for every kind of usage
- Code tends to stack in one tier, so it does not scale well
To solve those problems, another approach exists: clean architecture.
The clean architecture approach is close to hexagonal architecture and very close to the onion architecture.
The idea behind clean architecture is to separate the business logic at the center of the application, independent of the presentation / data access layer.
The main advantages of clean architecture are:
- allowing one to postpone decisions, such as changing the database
- making the code easier to test, since the code that cannot be tested should only be in one layer
- being versatile, since it can be applied for any kind of app
- being easy to read
- scaling well
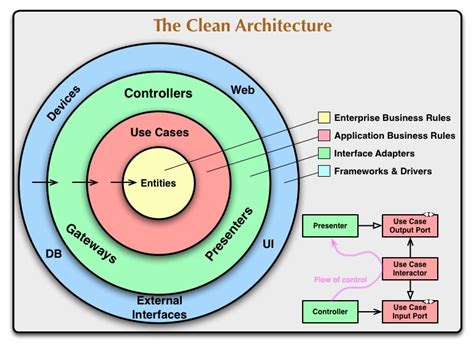
Entities encapsulate critical business rules. It could be an object with methods, or a set of structs and functions.
In a cooking app, it could be a struct describing a recipe, or a function to convert a gram into an ounce.
Use cases are the business rules. It implements all of what you can do with the app.
In a cooking app, this could be a function which creates a recipe and puts it in a database, or a function that takes recipes and returns a shopping list.
If you think this is counterintuitive, you’re right. We’ll see later on how a use case can use a database without breaking our architecture.
Interface adapters are components that adapt the use cases to be used by an external agency (e.g. database gateways, presenters).
It could be the controller of a MVC architecture of a GUI, or a database adapter.
Frameworks and drivers are the only components that communicate with the outside world.
This could be a class that talks to a SQL database, or a web API.
Some articles skip the interface adapters layer, and it is also possible to have more layers based on what is needed.
A practical example will be shown at the end of the article, where those concepts will be put in practice. But before, let’s see how a use case can talk to a database.
How to deal with dependencies between components
On the clean architecture picture that we saw before, the arrows point towards the entities. Each layer should only know about the layers it contains.
But how could a use case talk to a database? The answer is using inversion of control:
Instead of calling the functions of a lower layer, the lower layer depends on an interface, and the higher level passes an object that implements this interface to the lower layer.
Without inversion of control:
|
|
With inversion of control:
|
|
It is also easier to test the second version.
We can inject a fake database that does nothing for the sole purpose of testing.
Indeed, it avoids needing a real database, and the fake database behavior can be modified to test some corner cases.
This is called mocking.
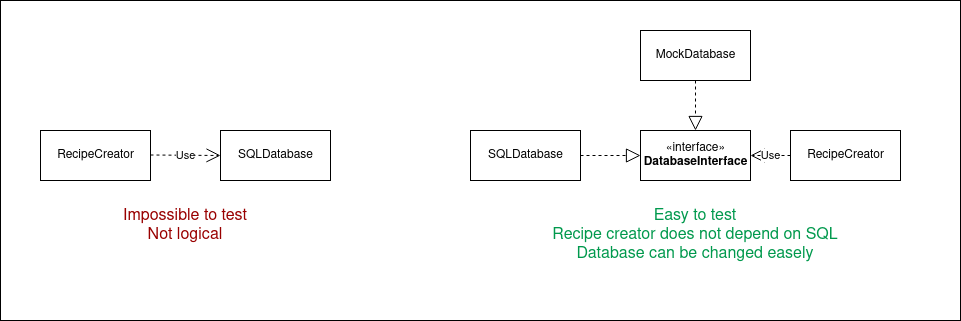
Here, the DatabaseInterface is a port and the SQLDatabase is an adapter.
Some basic principles should be respected when creating components, such as:
- ACP (acyclic dependencies principle): the dependency graph of packages of components should have no cycles.
- SDP (stable dependencies principle): less stable components should depend on more stable components.
- SAP (stable abstractions principle): stable components should be abstract, unstable components should not be abstract.
Stability can be defined by: S = (number of incoming dependencies) / (number of incoming and outgoing dependencies).
A component that uses no components and is used by many components is very stable.
A component that uses many components and is used by no component is not stable.
Abstractness can be defined by: A = (number of interfaces) / (number of classes and interfaces).
A component that contains just interfaces (or abstract classes) is very abstract.
A component that contains no interfaces (or abstract classes) is not abstract.
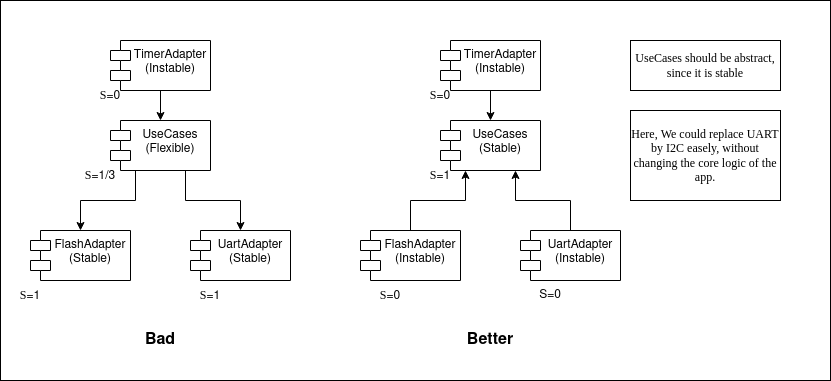
Remember: you can invert the dependency flow using inversion of control.
Recap - building a recipe app
Let’s apply all of the concepts we’ve seen before and build a TUI (terminal user interface) app to store cooking recipes. After defining our main use cases, we can start drawing an architecture.
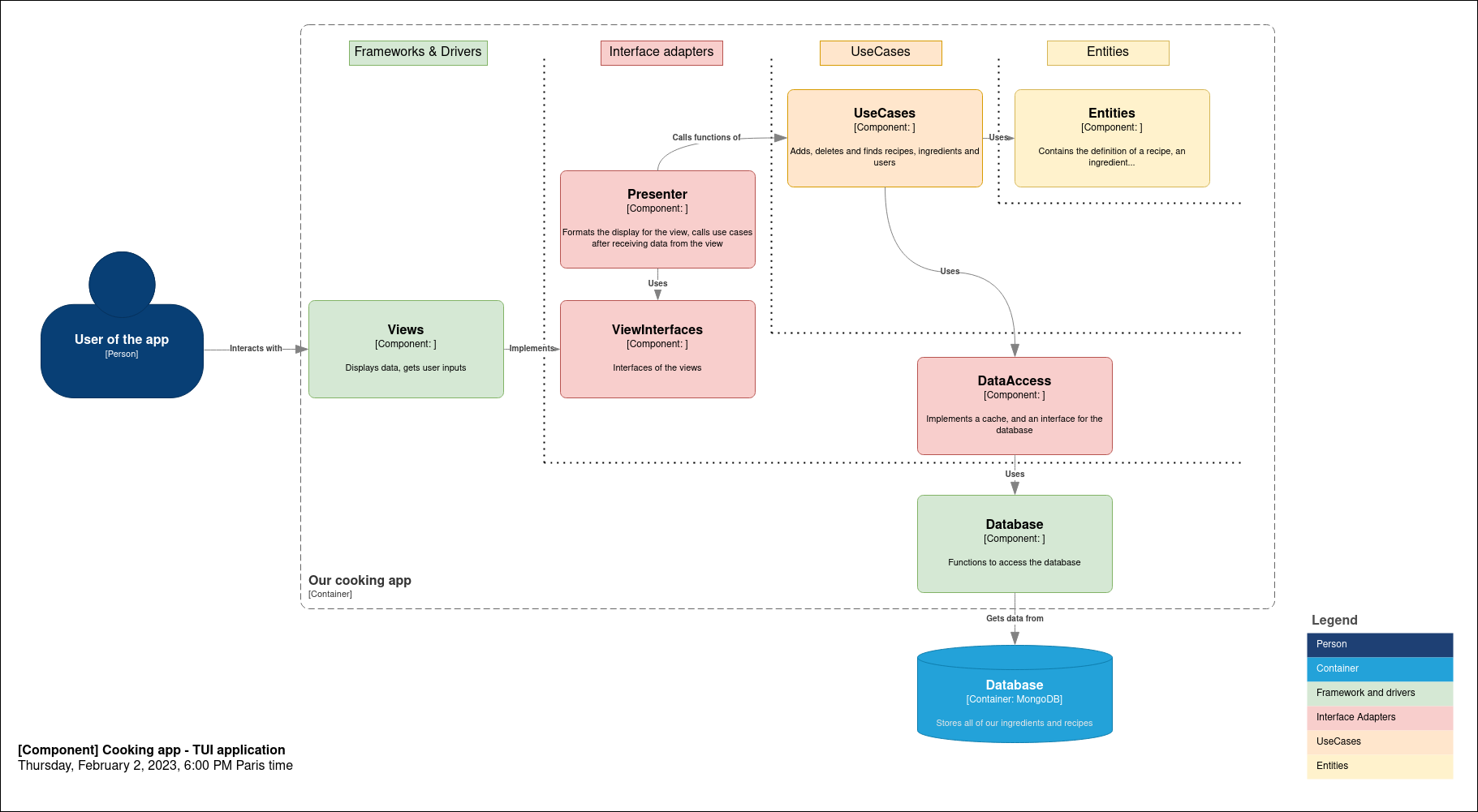
Did you find the problem?
Yes! The inner layers depends on the outer layers.
By using inversion of control, we can come up with something better.
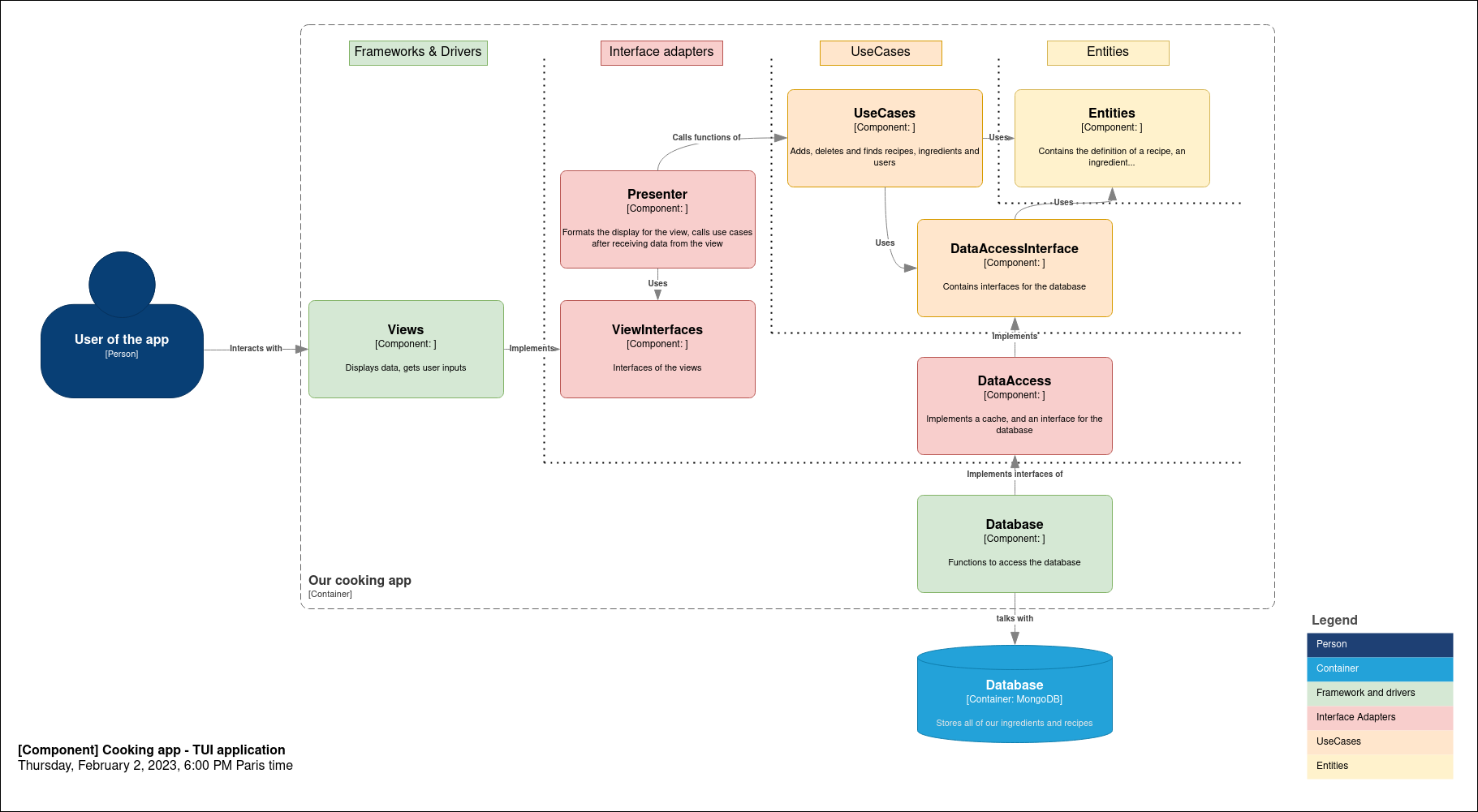
The use cases will describe the features of the app. In use_cases/recipe_use_cases.rs, we would have a AddRecipe(), FindRecipeContainingIngredients()…
The frameworks and drivers should respect the humble object pattern: be as simple as possible, since they cannot be tested (for example, testing the GUI is hard). Most of the code should rather be in the interface adapters.
Testing the app becomes straightforward: mocking the Views and Database allows us to test the code, without having to run a database.
As we can see, the ViewInterfaces (that has a stability of 1, since it does not have dependencies) and the DataAccessInterface (that has a stability of 2/3, since it has two incoming dependencies and one outgoing dependency) will be the most stable components. Since they should contain interfaces, they are abstract, which is logical according to the SAP.
The components that depend on those (Views and Database) are unstable (they both have a stability of 0), which is logical according to the SDP. And there are no cycles, so the ACP is respected.
The only exception would be the Entities component. It is very stable (it has a stability of 1) but not very abstract. This should be fine, as it should not change a lot.
After and only after defining our architecture, we can create the main interfaces, start BDD / TDD and apply the SOLID principles while coding.
The result will be way more maintainable than a three-tier architecture.
Sources
-
The C4 model : a tool to draw and visualize software. Fun fact : Simon Brown, the creator of the C4 model wrote a chapter in Uncle Bob’s “Clean Architecture”.